Paper: Efficient mapping of range classifier into Ternary-CAM.pdf;
Slide: Efficient mapping of range classifier into Ternary-CAM_ppt;
会议: Hot Interconnect 2002;
引用:150+;
作者:Huan Liu, 斯坦福大学;
级别:鼻祖类,极度重要,精读;
本文总结:
本文的核心创新点是解决range无法直接在TCAM中存储的问题(或者range expansion问题)。
本文所基于的主要observation是:1)The transport layer protocol field is restricted to a small set of exact values instead of a generic range;2)Only 10.2% specifications for transport layer fields are of generic range.而这中间Certain ranges are used in a large number of rules(~9%).因此,只有1.2%的distinct ranges. 总而言之, even though the number of rules in a classifier could be large, the number of distinct ranges specified for any range field is very limited.
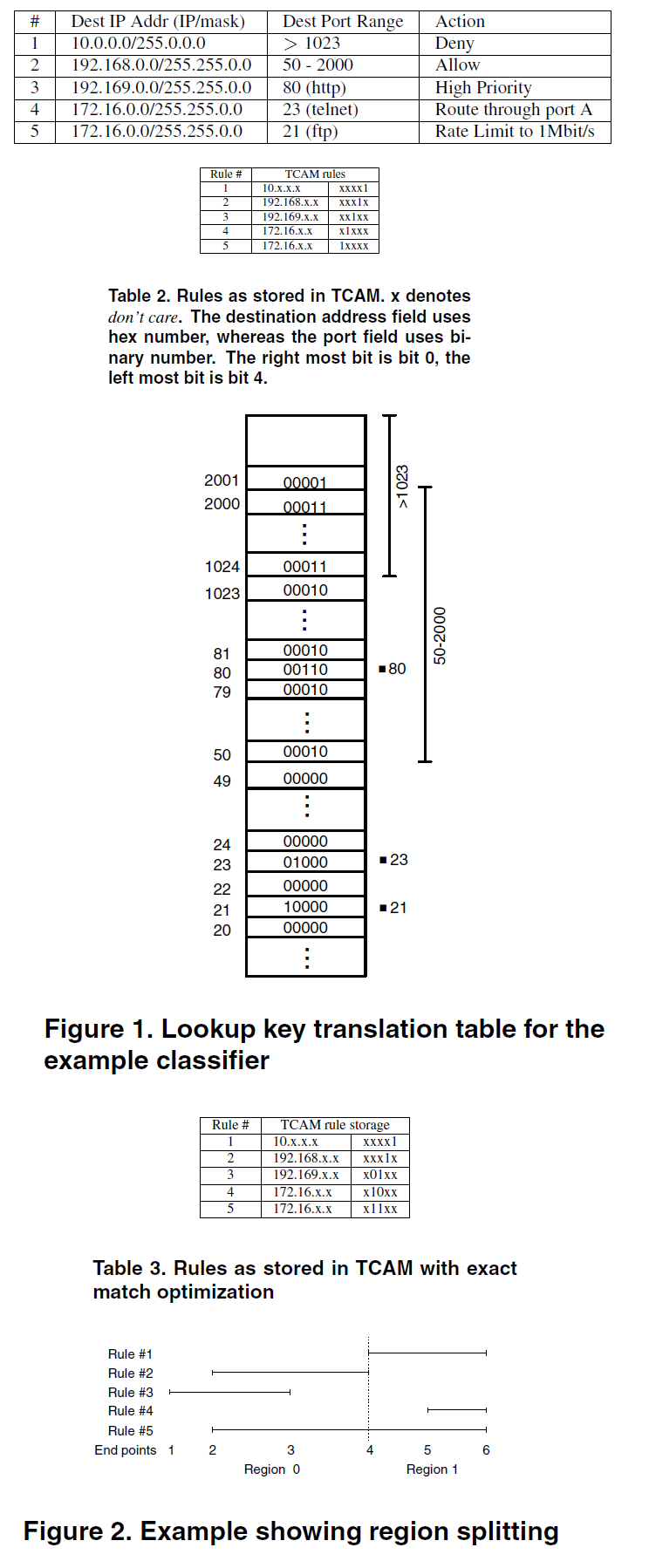
基于上述observation,作者脑门大开,想出了本文的核心思路:Since the number of distinct ranges is limited, we could use a single bit in an entry to represent each of them(e.g., 文中table2是对table1的represent).This set of bits is stored in TCAM instead of the original range.For every packet, we have to translate the lookup keys into their bit representation before matching against TCAM. The translation could be completed in a single memory access by direct table lookup(e.g.,文中figure1).也就是说,既然这样的distinct range很少,那么我们就可以进行三态编码,使每个三态码都与匹配的ranges对应,TCAM中存的是码字而不是range了,所以就消除了range expansion问题。TCAM中存的不是range,那么怎么查找?那就通过direct table来预先进行关键字转换(其实,本质是通过连续存储一次找到所有匹配的range,而查找表中存的码字正是对这些匹配range的唯一编码,后续的TCAM其实不过是在查找码字而不再是range!)。
优化手段1:精确值不再使用一个bit来表示,而只需要指数个bit编码对应,这样可以有效降低所需TCAM位宽;这一手段的reason是all exact matches are mutually exclusive. Namely, if the lookup key matches one exact match, it will not match another. 有意思的是,作者指出As long as the ranges involved are mutually exclusive, this optimization could be extended to normal ranges as well (可做点,next job,05年有不少论文做了这些事情!).
优化手段2:如果distinct ranges数目较多,TCAM的一个entry无法存储咋办?作者提出了region splitting优化方法,将range 集合划分成几个子集,使得每个子集可以在一个entry中编码存储(本质就是使用多个TCAM entry来表示一个rule,与range expansion有些类似)
Vincent点评:
很重要的一篇论文,处处是经典!Vincent觉得可能的问题有这样几点:1)direct table容量会不会有点大,能不能优化?2)规则集大了后是不是也会存在严重的expansion问题,因为规则集大了就需要进行大量的region splitting,实验结果显示,100条rule,位宽为12时需要15000entry,150的膨胀系数,即便位宽为32,膨胀系数大概也有10!3) 更新估计不好,尤其是在进行region splitting后!
Review From A. Liu

文中图表: